Today’s businesses must store an unprecedented volume of data and manage the depth and complexity of the data that they capture. Apache Hadoop, the framework that allows for the distributed processing of large data sets across clusters of computers, has gained in popularity because of its ability to handle large and diverse data types. Apache Spark, a fast and general engine for big data processing, has recently gained in popularity because of its ability to rapidly analyze data through its in-memory approach to processing and natively use data stored in a Hadoop File System (HDFS). Although some companies are successfully bursting to the cloud for these types of analytics, the options for ingesting and exporting data to and from these technologies have been limited in OpenStack until now.
Sahara Meets Manila
The OpenStack Shared File Systems project (a.k.a. Manila) provides basic provisioning and management of file shares to users and services in an OpenStack cloud. The OpenStack Data Processing project (a.k.a. Sahara) provides a framework for exposing big data services, such as Spark and Hadoop, within an OpenStack cloud. Natural synergy and popular demand led the two project teams to develop a joint solution that exposes Manila file shares within the Sahara construct to solve real-world big data challenges. This guide assists end users in the task of using this important new development in the OpenStack cloud capability. It examines common workflows for how a Sahara user can access big data that resides in Hadoop, Swift, and Manila NFS shares.
Introduction
One of the significant challenges for enterprises and service providers deploying big data applications is that workloads are typically dynamic or “bursty” in nature and yet require dedicated hardware setups. Dedicated setups sometimes result in wasteful deployment of compute and storage resources. Another problem is that, until recently, using internal cloud resources to serve the needs of big data processing was not feasible. The core infrastructure was difficult to implement and understand, and the task of layering the stack of applications and projects necessary to gain business value from the private cloud was daunting.
This landscape is changing, however, with the recent Liberty release of OpenStack. Core integration that enhances the ease of accessing data from Manila shares has been enabled in the OpenStack Data Processing service (a.k.a. Sahara). This article highlights and explains these developments. The OpenStack Data Processing service (and the project under which it is developed, Sahara) builds on the solid foundation of OpenStack cloud technology by exposing big data workloads to an OpenStack cloud user. In the past, Sahara was able to ingest data from a limited set of data sources.
Now, with the intersection of the capabilities of Sahara and the OpenStack Shared File Systems project (a.k.a. Manila), these workloads can access data that resides on NFS shares and other file stores and write result sets to them. This capability can be enabled through a couple of mechanisms. The Sahara and Manila projects’ cross-integration makes it possible to ingest large data sources from NFS shares either by accessing and managing existing shares or by provisioning new dedicated shares. In addition, job binaries, libraries, and configuration files can also reside in a shared Manila file-share location in Sahara to enable easier and more seamless distribution throughout a Hadoop or Spark cluster.
Existing Challenges
Before the Liberty release of OpenStack, the data source options in the Sahara big data project were limited. This limitation made life difficult for operators of Sahara clusters and prevented them from accessing data that was not in the two supported formats: HDFS and Swift. In addition, no accepted method for automating the provisioning of a shared file store was available. For data sources, the user had two options:
-
HDFS. Data residing in an existing HDFS file system could be accessed by Hadoop or Spark jobs.
-
Swift. Data in a Swift object store could be accessed at the swift URL. An additional challenge was that the job binaries, libraries, and configuration files required for a job definition had to be stored in Swift or in the Sahara internal database.
New Developments in Manila and Sahara
Sahara is a rapidly developing project. Below I have highlighted some recent changes that were implemented in the project to enable the features covered here. With the Liberty release, job binaries, libraries, and configuration files can be placed on a Manila share and accessed by all nodes in a Hadoop cluster through common mount points. This change eliminates the need for distributing files and configurations throughout multiple nodes.
The following changes in the Liberty OpenStack release position Manila as an integrated solution for Data Processing in Sahara:
-
Manila as a runtime data source - http://specs.openstack.org/openstack/sahara-specs/specs/liberty/manila-as-a-data-source.html
-
Addition of Manila as a binary store - http://specs.openstack.org/openstack/sahara-specs/specs/liberty/manila-as-binary-store.html
-
API to mount and unmount Manila shares to Sahara clusters - http://specs.openstack.org/openstack/sahara-specs/specs/liberty/mount-share-api.html
So how does all this fit together?
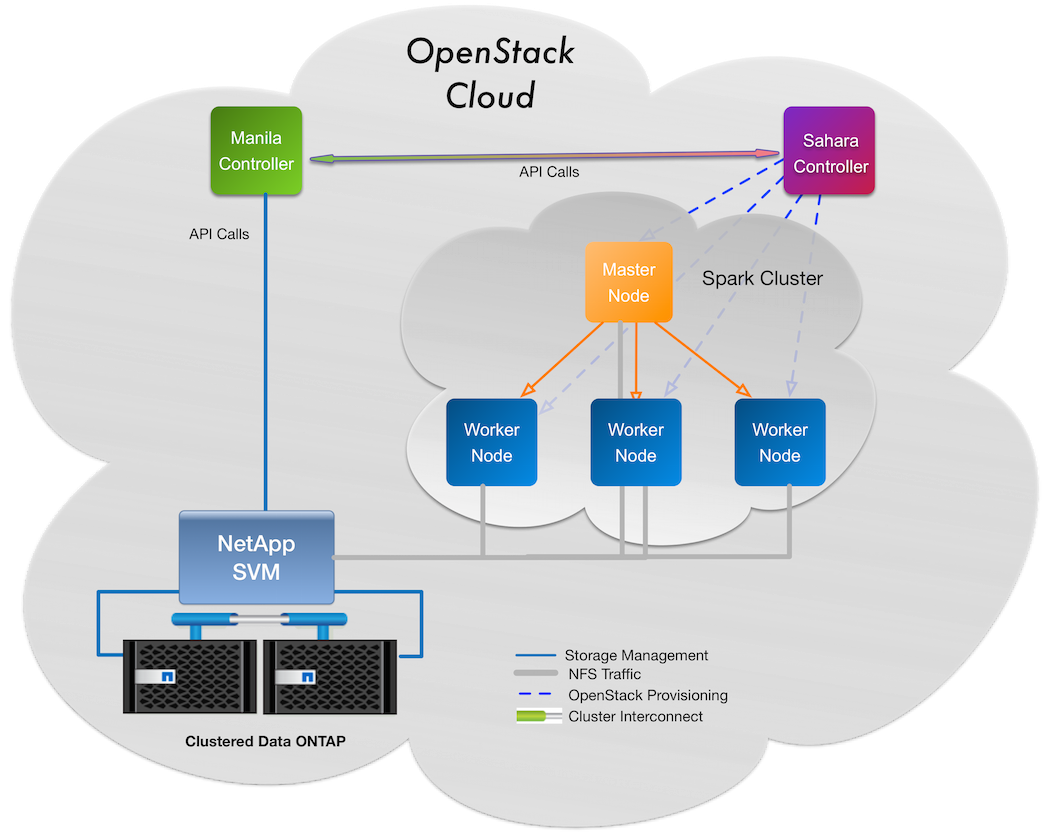
Sahara and Manila together offer strong usability for big data administrators. The above image depicts a workflow that enables administrators to bring data into Sahara from enterprise data sources that reside on NetApp NFS storage. The workflow also enables administrators to save the resultant datasets to the same shares or to different shares for purposes of distribution, further analysis, and so forth. This solution is based on new integration work by the Sahara and Manila project teams. This workflow illustrates how an administrator of Sahara can move data between traditional sources such as HDFS and the newer NFS Manila-based data source.
So let’s look at this more closely. Starting at the Sahara controller (top right), the administrator creates a Spark cluster that results in four Spark instances: a master and three slaves. The Sahara service handles all API calls to the Manila service to add access based on a Manila data source object that was pre-created and predefined in our cluster template. Shares are automagically mounted by Sahara within the Spark cluster nodes and are accessible by them for input or output operations as well as for job binaries, libraries, and so on. No more copying files around or putting them in object stores that don’t really make sense for many use cases.
Pretty easy right? The promise of shared files in an OpenStack cloud is now a reality. And watch for more use cases to come. Database as a service? Shares for a VDI infrastructure? All of these are within quite close reach with the maturation of Manila in Liberty. Stay tuned. “You ain’t seen nothing yet!”
How can I get it?
All of this information and more is documented in exquisite detail in a newly released technical report which can be found at:
https://www.netapp.com/us/media/tr-4464.pdf
In this document you will find information on setting up Manila shares, cluster templates that utilize them, and examples of how to run real Spark jobs from and to these new data sources. The life of a Big Data administrator just got a lot easier thanks to the joint work of RedHat and NetApp and our friends in the Manila and Sahara communities who all helped make this possible!