

Document-Based RAG with NetApp
1. Introduction
This project captures a Document-centric Retrieval-Augmented Generation (RAG) architecture developed and validated by NetApp.
The focus is on building RAG systems that are explainable, deterministic, and governance-ready from day one. Instead of defaulting to vector-only retrieval, this architecture uses BM25 lexical search, enriched with explicit entity extraction, to make every retrieval decision observable and reproducible.
The complete reference implementation, including open source code and step-by-step guides, lives here: 👉 https://github.com/NetApp/document-rag-guide
This page serves as the NetApp-specific overview and entry point.
2. Why Document RAG
Most RAG stacks begin with embeddings and end with uncomfortable questions:
- Why did this document match?
- Which terms mattered?
- Can we reproduce this result tomorrow?
- Can we prove compliance?
Document-based RAG flips that model.
Instead of treating retrieval as an opaque side effect of embeddings, it treats retrieval as a first-class, auditable system.
Key reasons this approach works:
Explainability by default: BM25 matches explicit fields and terms. You can point to the exact reason a document was retrieved.
Deterministic behavior: The same query over the same data produces the same result. No hidden ranking drift.
Reduced hallucinations: LLM responses are grounded in retrieved documents, not semantic "near matches."
Clear governance boundaries: Explicit document metadata, entity fields, and retention policies make audits practical instead of theoretical.
Vectors still exist, but only as augmentation, never as the sole authority.
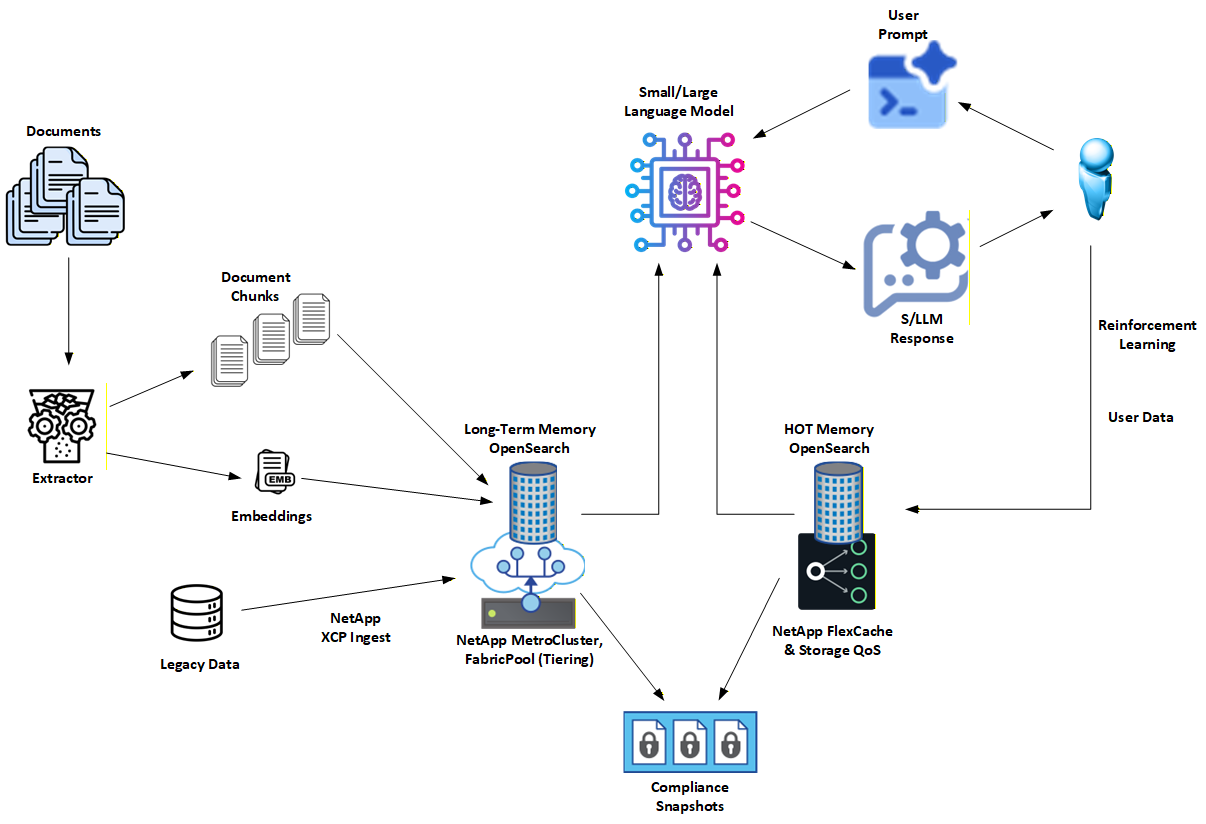
3. How NetApp Enhances This Architecture
NetApp extends Document RAG with enterprise-grade data management and storage capabilities that turn a clean design into a deployable system.
Key NetApp-specific enhancements include:
Dual-tier memory model
- Long-Term (LT): authoritative, durable document store
- HOT (unstable): short-lived, user- or session-specific working set
Governance-driven isolation
- HOT exists to enforce retention, policy asymmetry, and blast-radius control
- LT remains stable, conservative, and audit-ready
High-performance locality
- NetApp FlexCache keeps frequently accessed documents close to compute
- Cache eviction is explicit and policy-driven, not accidental
Enterprise resilience
- SnapMirror and MetroCluster support replication and disaster recovery
- Snapshots enable point-in-time audits of "what the AI knew"
Safe experimentation
- FlexClone enables instant copies of indices for testing new analyzers or embeddings without impacting production
The result is a Document RAG architecture that aligns with how enterprises already manage data: explicit, observable, and controlled.
4. Visit the GitHub Project for More Details
This page is intentionally high-level.
For full technical details, code, and deployment guidance, visit the main project:
👉 https://github.com/NetApp/document-rag-guide
There you'll find:
- A fully open source, community-runnable implementation
- An enterprise architecture with HOT/LT separation and promotion workflows
- Clear patterns for explainable, compliant retrieval
If your goal is AI you can explain, reproduce, and defend, start there.