

Hybrid RAG with NetApp
BM25 + Vector Retrieval with Governance Built In
1. Introduction
This project highlights a Hybrid Retrieval-Augmented Generation (Hybrid RAG) architecture developed and validated by NetApp.
The design combines BM25 lexical search for deterministic, explainable grounding with vector embeddings for semantic coverage. The result is a retrieval system that balances precision and recall while remaining observable, auditable, and enterprise-ready.
This page provides a NetApp-focused overview of the architecture and its enterprise implications. The full open source reference implementation lives here: 👉 https://github.com/NetApp/hybrid-rag-bm25-with-ai-governance
2. Why Hybrid RAG
Pure vector RAG is good at "semantic vibes" but weak at answering hard questions like:
- Why did this document match?
- Which terms actually mattered?
- Can we reproduce this result next week?
- Can we defend it to auditors?
Hybrid RAG addresses those gaps by anchoring retrieval in BM25 first, then using vectors as supporting context, not the source of truth.
Key reasons Hybrid RAG works:
Deterministic grounding: BM25 provides explicit, traceable matches against known terms and entities.
Semantic coverage without drift: Vector embeddings expand recall for paraphrases and long-tail phrasing without replacing lexical evidence.
Explainability by design: Every result can be tied back to fields, terms, and highlights rather than opaque similarity scores.
Lower hallucination risk: LLM responses are grounded in retrieved documents with clear provenance before any stylistic refinement.
Practical governance: Retrieval behavior is inspectable and reproducible, which matters in regulated environments.
This approach delivers many of the governance benefits people look to Graph RAG for, without the operational overhead of graph databases or ontology management.
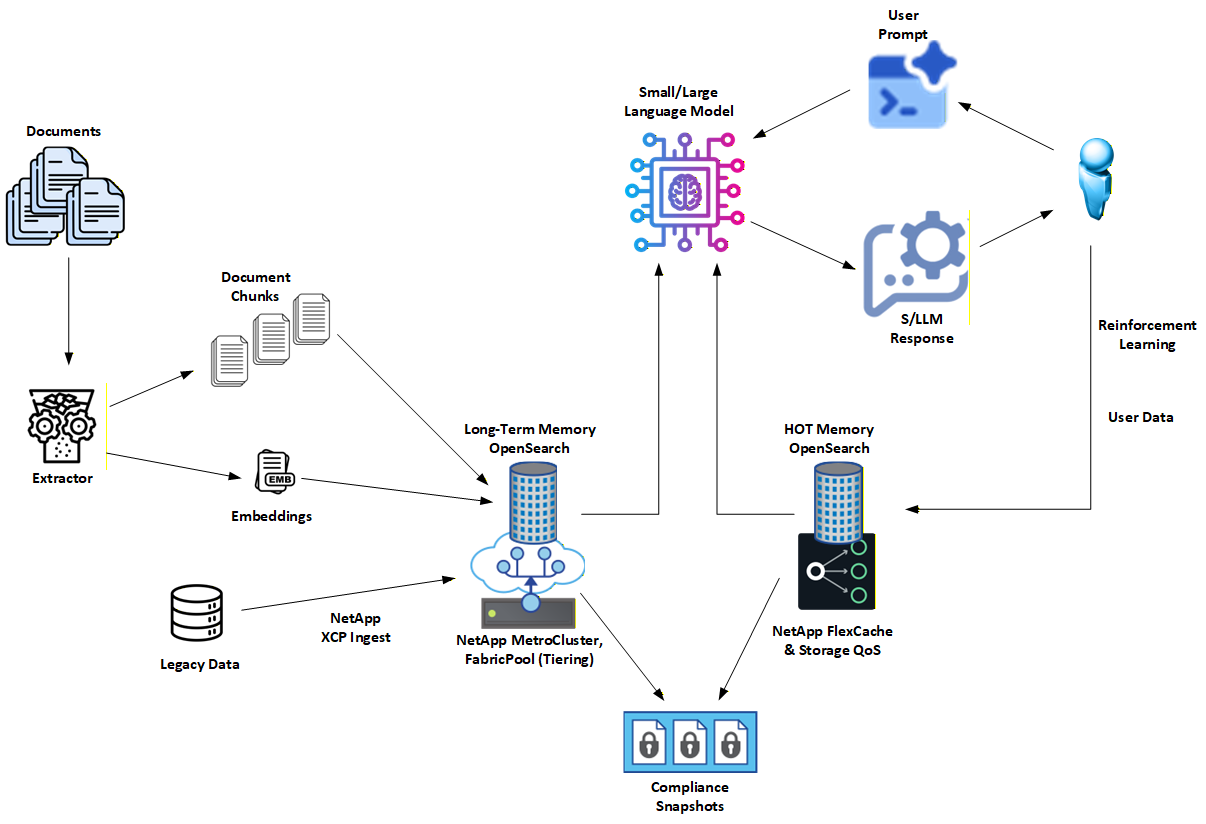
3. How NetApp Enhances This Architecture
NetApp extends Hybrid RAG with enterprise-grade data management and storage primitives that make the architecture operational at scale.
Key NetApp contributions include:
Dual-tier memory model
- Long-Term (LT): authoritative, durable knowledge store
- HOT (unstable): short-lived, user- or session-specific working set
Governance-first tiering
- HOT exists for retention control, policy asymmetry, and isolation
- LT remains conservative, stable, and audit-ready
High-performance locality
- NetApp FlexCache keeps frequently accessed shards close to compute
- Eviction is explicit and policy-driven, not accidental
Enterprise resilience and compliance
- MetroCluster protects Long-Term graph and vector stores with synchronous replication and zero-RPO posture
- SnapCenter captures application-consistent snapshots of Neo4j and OpenSearch state
- SnapLock adds WORM protection for environments that require immutable evidence and audit trails
Safe experimentation
- FlexClone allows instant, space-efficient copies of indices for testing new analyzers or embedding models without touching production
NetApp's role is not to change how Hybrid RAG works logically, but to make it reliable, governable, and operable in real enterprise environments.
4. Visit the GitHub Project for More Details
This page is intentionally concise.
For full technical details, code, and deployment guidance, visit the open source project:
👉 https://github.com/NetApp/hybrid-rag-bm25-with-ai-governance
There you'll find:
- A complete Hybrid RAG reference implementation
- Community and enterprise deployment paths
- Detailed explanations of BM25 grounding, vector augmentation, and HOT/LT promotion workflows
If you're building RAG systems that need to be accurate, explainable, and defensible, that repository is the place to start.