

Graph RAG with NetApp
1. Introduction
This project documents a Graph-based Retrieval-Augmented Generation (Graph RAG) architecture developed and tested by NetApp.
The goal is simple: show how enterprises can build AI systems that are explainable, governable, and production-ready, not just clever demos. Instead of relying only on vector embeddings, this architecture uses knowledge graphs with explicit relationships, combined with a dual-memory model that separates authoritative knowledge from fast, conversational context.
The full reference implementation, including open source code and detailed walkthroughs, lives here: 👉 https://github.com/NetApp/graph-rag-guide
This repository serves as the NetApp-focused entry point and architectural overview.
2. Why Graph RAG
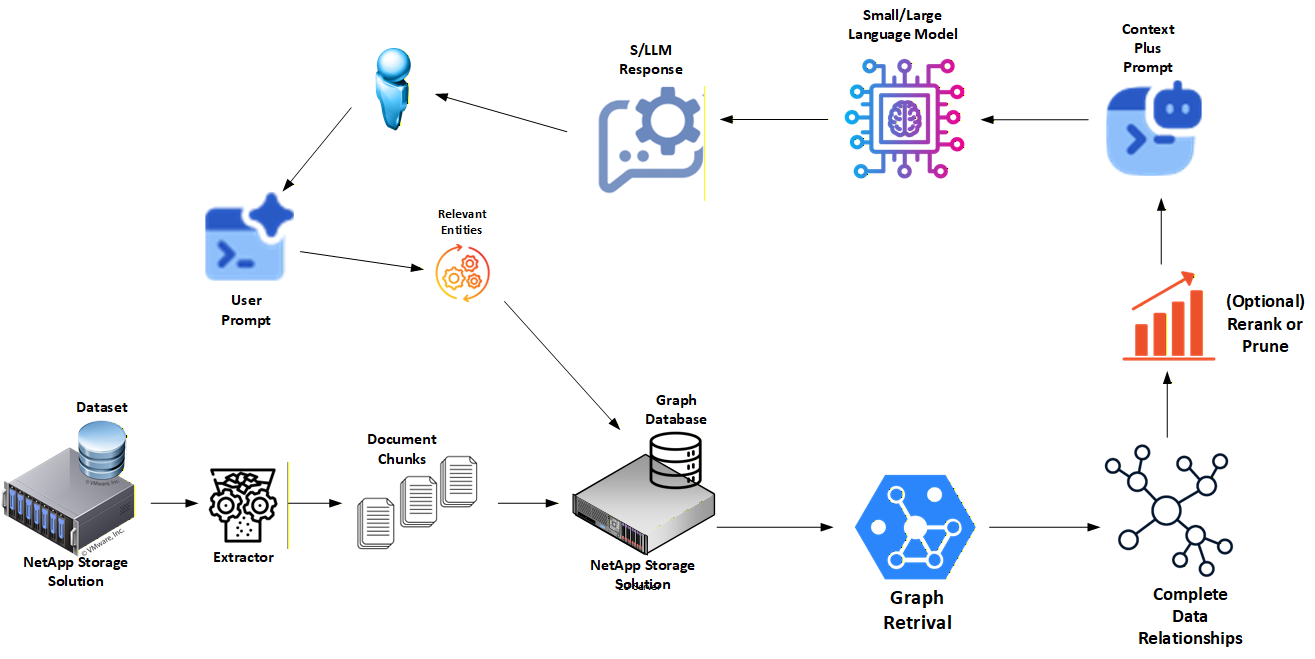
Traditional RAG pipelines usually start and end with vector search. That works for similarity matching, but it breaks down when teams need:
- Clear explanations for why an answer was returned
- Auditable data lineage and provenance
- Multi-hop reasoning across related facts
- Strong governance and compliance controls
Graph RAG addresses these gaps by storing knowledge as nodes and relationships instead of opaque embeddings.
Key advantages include:
Reduced hallucinations: Responses are grounded in explicit graph paths, not nearest-neighbor guesses.
Explainability by design: Every answer can be traced through readable graph queries.
Better governance: Provenance, confidence, and promotion logic live directly in the data model.
Multi-step reasoning: Graphs naturally support traversals across documents, entities, and concepts.
This architecture treats retrieval as a first-class system, not a side effect of embeddings.
3. How NetApp Enhances This Architecture
NetApp extends the core Graph RAG design with enterprise-grade data and storage capabilities that make it practical at scale.
Key enhancements include:
Dual-memory architecture
- Long-term memory for authoritative, durable knowledge
- Short-term memory for fast, conversational context
High-performance caching
- NetApp FlexCache enables microsecond-level access to hot graph data
- Cached data expires automatically to prevent stale knowledge
Data mobility and resilience
- SnapMirror provides replication and recovery across sites
- Storage follows workloads, not the other way around
Promotion and reinforcement workflows
- Frequently used or validated facts are promoted from cache to long-term memory
- Confidence, provenance, and audit metadata are preserved end-to-end
Operational readiness
- Designed to integrate with streaming pipelines and production infrastructure
- Supports regulated environments where traceability is non-negotiable
The result is a Graph RAG architecture that aligns with real enterprise constraints: performance, governance, and scale.
4. Visit the GitHub Project for More Details
This page is only a summary.
For full architecture diagrams, implementation details, and runnable examples, visit the main project:
👉 https://github.com/NetApp/graph-rag-guide
There you'll find:
- A community, open source reference implementation
- An enterprise-grade architecture with promotion and governance patterns
- Clear upgrade paths from laptop demos to production deployments
If you're building AI systems that need to be trusted, explained, and operated long-term, start there.